{kind=link}
The origins of linear time series analysis go back pretty much as far as those of statistics itself*. As soon as someone has a sequence of numbers they care about, "what comes next?" is a pretty natural question. Once the technology of linear least-squares modeling existed, it was equally natural that people would try to use it for time-series forecasting. This tendency was encouraged by some very deep results obtained Hermann Wold in the 1930s, which, roughly speaking, said that any well-behaved ("weakly stationary") time series, $X_t$, could be represented either as a linear regression on all its own past values plus noise (an "infinite-order autoregression"), \[ X_t = a_0 + \sum_{j=1}^{\infty}{a_j X_{t-j}} + D_t \] or as a weighted sum of an infinite sequence of noise terms (an "infinite-order moving average"), \[ X_t = b_0 + \sum_{j=1}^{\infty}{b_j D_{t-j}} ~. \] These sums really do need to be of infinite order for the decomposition to hold, and while the noise terms $D_t$ can be arranged to be uncorrelated, they will generally not be independent or have identical distributions (i.e., they will not be "IID"). They will certainly not generally be Gaussian.
Nonetheless, Wold's results helped lead to the articulation of an elaborate machinery of finite-order autoregressive and moving-average models, including hybrid autoregressive-moving-average ("ARMA") models, with IID Gaussian noise, where \[ X_t = a_0 + \sum_{j=1}^{p}{a_j X_{t-j}} + \sum_{k=1}^{q}{b_k D_{t-k}} + D_t ~, \] with $D_t$ all uncorrelated mean-zero Gaussians with the same variance. Despite its lack of genuine stochastic foundations, this ARMA machinery had the great virtue of being implementable by those trained in linear regression, and it was eagerly adopted by many users. (It would be wrong to say that, while economic theory gives no reason to expect economic time series should follow ARMA models, they became the alpha and omega of time series econometrics; they are merely the alpha.) When attempts were made to get beyond this sort of model, to deal with nonlinear processes, or higher moments of the distribution than just the conditional mean, these were often deliberately patterned on the ARMA technology, not because it made particular sense in terms of stochastic process theory, or statistical inference, or scientific knowledge of what was being modeled, but because it was tractable, and could be implemented with minor tweaks to existing ARMA tools. (These extensions of ARMA are the omega of time series econometrics.) This technology can be spun out almost endlessly, and has been, to great acclaim.
Most time series textbooks concern themselves with exclusively with the ARMA technology**. Fan and Yao cover it in their first four chapters, totaling just under 200 pages. (And some of those pages are general theory of stochastic processes, of broader application.) This seems to me about the upper limit of the attention this material merits for contemporary readers. Chapters 5--10, running about 300 pages, are given over to modern non-parametric methods for time series: estimating the marginal density; estimating conditional expectations; smoothing and removing trends and periodic components; estimating the spectral density or power spectrum; estimating the conditional variance; estimating conditional distributions and prediction intervals; validating predictive models; and testing hypotheses about stochastic processes. Parametric specifications, like the ARMA model, are completely avoided, in favor of estimating the relevant functions directly from data, essentially just by sitting, waiting, and averaging.
To see how this might hope to work, consider just the problem of guessing at the expected value of $X_{t+1}$ given $X_t$, \[ \mathbb{E}\left[X_{t+1}\mid X_t=x\right] \equiv m_t(x) ~ . \] (Using this predictor doesn't commit us to assuming that nothing which happened before $t$ matters for the future; we are choosing to ignore those events, not positing their irrelevance.) Suppose that the relationship between the two variables is stable, so $m_t(x)$ doesn't depend on $t$ and we can drop the subscript. Suppose further that we've observed a particular time series, $x_1, x_2, \ldots x_T$. In the ARMA world, we select the "orders" $p$ and $q$, and step through maximum likelihood. In the non-parametric world, we attempt to estimate the relationship between $X_{T+1}$ and $X_t$ in a less bias and prejudicial way. Suppose we want to make a prediction about what $X_{t+1}$ will be when $X_t = 0$. One simple non-parametric approach would be to pick a "bandwidth" $h$, and find all the points in the time series where $x_t$ was within $h$ of 0. A reasonable guess for what $X_{t+1}$ will be is then the average of the corresponding $x_{t+1}$: \[ \widehat{m}_h(0) = \frac{\sum_{t: |x_t| < h}{x_{t+1}}}{\sum_{t: |x_t| < h}{1}} = \frac{1}{N_h}\sum_{t: |x_t| < h}{x_{t+1}}~. \] where $N_h$ is the number of time-points $t$ where $x_t$ falls within the averaging window. I have written a hat over the $m$ as a reminder that it is not the true function, but only an estimate of it. There are two sources of error in this estimate: noise and approximation.
Noise is straightforward: the estimate is based on only a limited number of samples, each of which includes some stochastic fluctuation. For reasonable ("ergodic") time series, if we extend $T$, then the number of points we average over, $N_h$, will grow proportionally to $T$, so the average will converge on an expectation value, and the sampling noise goes away. Under some fairly weak assumptions, the variance of the sampling noise in this estimate goes to zero like $1/hT$, "is $O(1/hT)$", with the factor of $h$ reflecting the fact that larger bandwidths will lead to averaging over proportionately more samples.
Approximation error is slightly trickier. The expectation value this estimate converges on is \[ \mathbb{E}\left[\widehat{m}_h(0)\right] =\mathbb{E}\left[X_{t+1}\mid X_t \in (-h,h)\right] ~, \] whereas we want \[ m(0) = \mathbb{E}\left[X_{t+1}\mid X_t = 0\right] ~. \] How big is this systematic approximation error? An only slightly-complicated argument*** shows that \[ \mathbb{E}\left[\widehat{m}(0)\right] - m(0) = O(h^2) ~. \] That is, the systematic approximation error, or "bias" grows like the square of the bandwidth.
To get the total mean-squared error, we need to square the bias and add it to the variance, so the over-all error is \[ s^2 + O(h^4) + O(1/Th) \] where $s^2$ is the error we'd have even if we knew the true prediction function $m(0)$. The first term, $s^2$, is just a fact of life, set by the dynamics of the underlying data-generating process. But the other two terms are under our control, because they involve the bandwidth $h$. To put the formula in words, if we make the bandwidth small, we average only over points which are really close to our operating point of 0, so the systematic approximation error is reduced. But there aren't very many of those, so we average over few observations and are subject to noise. Conversely, increasing the bandwidth stabilizes our prediction (because we average away the noise), but increases the approximation error.
There is an optimal bandwidth which finesses this trade-off between approximation error and instability as well as possible. Elementary calculus tells us that $h_0 = O(T^{-1/5})$. Notice that this changes with $T$ — as we get more data, we can shrink the bandwidth, and, averaging over finer and finer scales, reveal more and more of the structure in the prediction function $m$. In fact, if we knew $h_0$, or an Oracle told us, our excess mean-squared error, over $s^2$, would be $O(T^{-4/5})$. For an ARMA model, on the other hand, the excess mean-squared error is $O(r+T^{-1})$, the additive constant $r$ reflecting the ineradicable systematic error that comes from the fact that the ARMA model is mis-specified. The conventional technology converges faster, but to a systematically wrong answer. This can still be useful, especially if you don't have much data (so that $T^{-1}$ is noticeably smaller than $T^{-4/5}$), but the local-averaging method ultimately wins.
Obviously, there is nothing special about making the prediction at $X_t = 0$; we could make it in the vicinity of any point we like. (This would mean averaging a different set of example points, depending on where we want to make a forecast.) We don't have to give every point within the averaging window equal weight; we can use smooth "kernel functions" to give more weight to those which are closer to those which are closer to the point where we want to make a prediction. This is called "kernel smoothing". Finally, we don't have to just take a weighted average; since we like linear regression so much, we could do one on just the historical points that fell within the bandwidth region. (The approximation error is then still $O(h^2)$, but the constants are smaller.). This "local linear regression" means solving a different linear least-squares problem for each prediction, but thanks to 200 years of concentrated attention by very smart numerical algorithm designers, linear least squares is fast.
I have spoken so far about what we could do if the Oracle told us $h_0$. What are we to do now that the Oracle has fallen silent (perhaps out of hurt and resentment)? The key trick is to realize that the best bandwidth is defined as the one which allows the best generalization from old data to new data. We can emulate this by dividing the data into parts, fitting our model to one part with a range of bandwidths, and seeing which one does best at predicting the rest of the data. There are a lot of wrinkles to this idea of cross-validation, and I won't here go into the details, or into the alternatives, but the key property is that if we do it right, we select a bandwidth which is very close to what the Oracle would have told us, so close that our over-all error is still $O(T^{-4/5})$. In the jargon, non-parametric smoothing "adapts" to the properties of the unknown data-generating process, which lets us discover those properties.
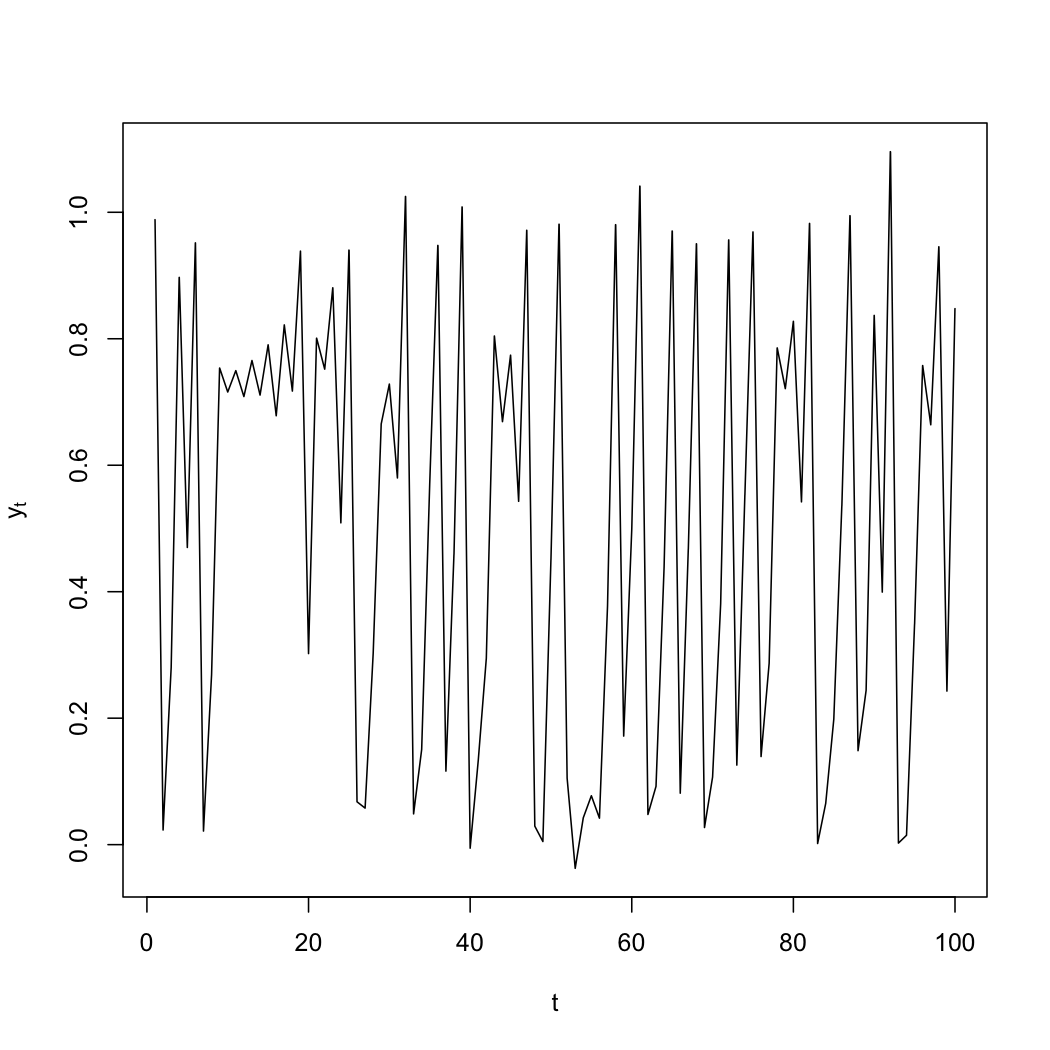
Let me be a bit more concrete, by running a little simulation and treating it like real data. Here is the beginning of a time series I generated from a nonlinear model (the logistic map, plus Gaussian noise, if you care):
If I make a scatter-plot of successive values against each other, there's pretty clearly a lot of structure:
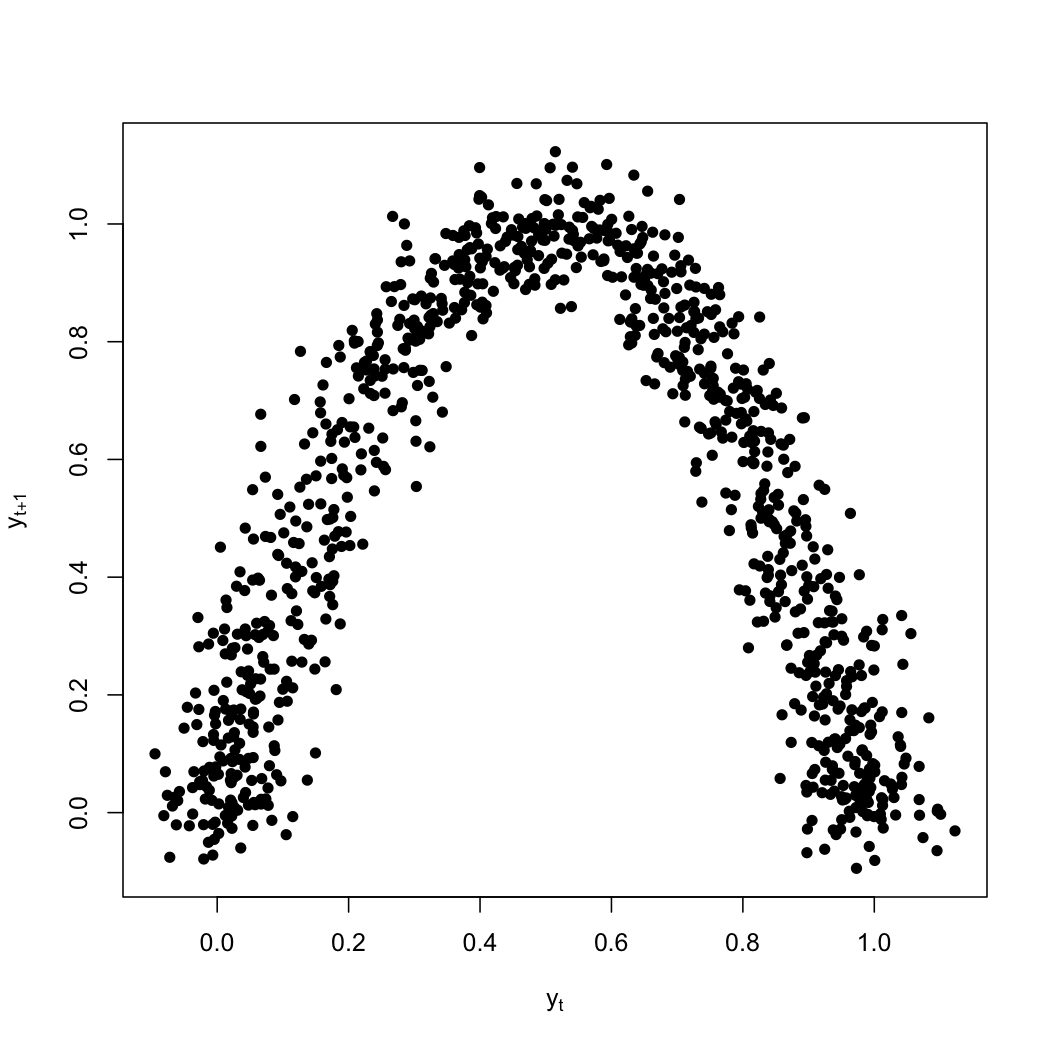
Linear regression is of course quite unable to find this structure; the red line here is the best-fitting line, which would correspond to an AR(1).

Using more flexible ARMA models doesn't help; for instance, if I go out to an AR(8), where each point is linearly regressed on the eight previous values, my predictions are still basically flat.
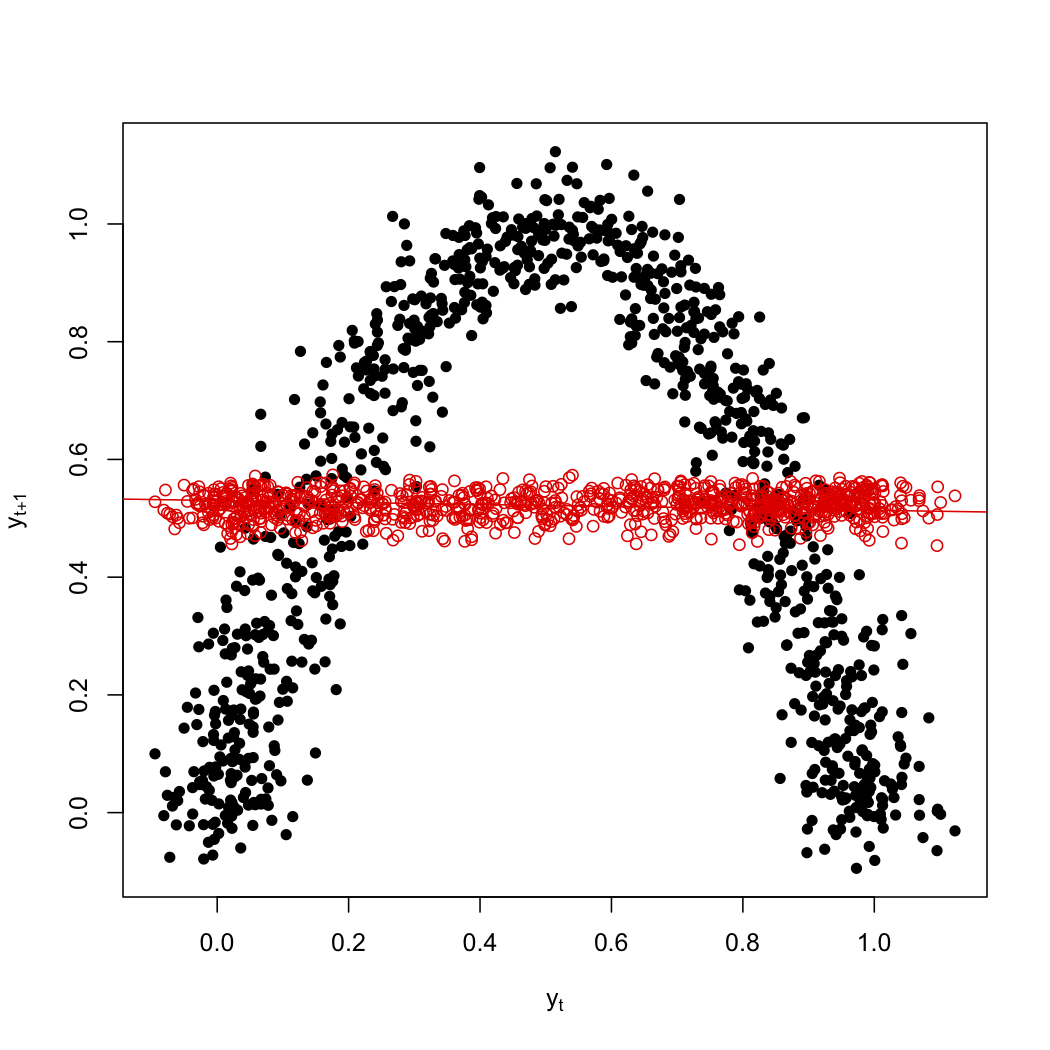
On the other hand, a straight-forward nonparametric smoothing picks up the obvious structure (blue points):

The foregoing was a deliberate caricature: just enough of the key features, exaggerated, to be recognizable, with all the other details suppressed. Fan and Yao do not deal in caricatures, and give a rather thorough account, on the statistical side, of kernel smoothing and local liner regression; of the alternative smoothing technology called "splines"; and of the difficulties all of these can run into when using not just one but many predictor variables, and the solutions, like additive models. (Their other main statistical tools are the bootstrap and cross-validation, about which they say less.) On the stochastic side, they rely on central limit theorems under mixing conditions for the convergences which I blithely assumed above. Their results are either asymptotic or empirical; there is no attempt at finite-sample performance guarantees. Many proofs are only sketched, or referred in their entirety to papers. The emphasis is consistently on statistical methodology, rather than on statistical theory****.
In principle, this could be read by someone with no previous exposure to either time series analysis or to non-parametric statistics, but a basic knowledge of probability theory, linear regression and statistical inference. In practice, it should be fairly straightforward (though not effortless) reading for someone ignorant of the usual time series technology but acquainted with non-parametrics (at the level of, say, Simonoff's Smoothing Methods in Statistics, or Wasserman's All of Nonparametric Statistics). Going the other way, and teaching non-parametrics to an ARMA-mechanic, would I suspect be harder going. There are no problem sets, but there are lots of examples, many with economic or financial content, and reproducing them, and filling in the steps of the proofs, would provide plenty of work for either a class or self-study.
Naturally, there are things I wish it did more of: there is nothing on state-space or hidden-Markov models (let alone state-space reconstruction), and little on fitting or testing stochastic models based on actual scientific theories of the data-generating mechanism*****. Non-parametric estimation of conditional distributions also gets less attention than I feel it deserves. On the computational side, let's just say that this book was finished at the end of 2002, and it shows. Still, it's at least as good as anything I've seen on statistical methods for nonlinear time series which has been published since. A second edition would, however, be very welcome. In the meanwhile, if we are going to continue to rely on time series models, this is a good place to start.
*: Klein's Statistical Visions in Time: A History of Time Series Analysis, 1662--1938 is a surprisingly readable history of these developments. ^
**: To my mind, the two best of these textbooks
are Shumway
and Stoffer (more elementary)
and Brockwell
and Davis (more theoretical). (Disclaimer: I know
Stoffer, and
Brockwell's son is a colleague.) ^
***: Re-write our local averaging estimate
in terms of the function we are trying to find and the stochastic noise which
disturbs observations away from it:
\[
\begin{eqnarray*}
\widehat{m}_h(0) & = & \frac{1}{N_h}\sum_{t: |x_t| < h}{x_{t+1}}\\
& = & \frac{1}{N_h}\sum_{t: |x_t| < h}{m(x_t) + D_t}
\end{eqnarray*}
\]
The noise terms $D_t$ are generally correlated, but they've all got expectation
0, and just contribute to the noise in the estimate. (I sketched how to deal
with them above.) The systematic approximation error, which is what we're
concerned with here, comes from the fact that the $m(x_t)$ are not all the same
as $m(0)$. To see how far off this puts us, use the fact that all the $x_t$
are close to zero, to justify
(what
else?) Taylor-expanding $m$ around zero:
\[
\begin{eqnarray*}
\mathbb{E}\left[\widehat{m}_h(0) \right] & = & \mathbb{E}\left[m(X_t)\mid X \in
(-h,h) \right]\\
& = & \mathbb{E}\left[m(0) + Xm^{\prime}(0) + \frac{X^2}{2}m^{\prime\prime}(0)
+ o(h^2)\mid X \in (-h,h)\right]\\
& = & m(0) + m^{\prime}(0) \mathbb{E}\left[X\mid X \in (-h,h)\right] +
\frac{m^{\prime\prime}(0)}{2}\mathbb{E}\left[X^2\mid X \in (-h,h)\right]
\end{eqnarray*}
\]
(I have tacitly assumed that the number of sample points in the
averaging window tells us nothing about where those points within the
interval. This assumption can be weakened at some notational cost in tracking
the dependence.)
Naively, then, one would think the systematic error of approximating $m(0)$
in this manner would be $O(m^{\prime}(0) h)$. Reflect, however, that if the
density of $X$ is symmetric around zero, then there would be no net
contribution from $m^{\prime}(0)$ --- data points to the right of zero,
introducing one error of order $hm^{\prime}(0)$, will be canceled out by data
points on the left of 0, introducing an error of order $-hm^{\prime}(0)$. To
get a net error contribution from the linear term, we need the samples to be
biased to one side of 0 or other, and this bias will be proportional to
$hf^{\prime}(0)$, where $f$ is the density of $X$, for a total contribution to
the error of $O(m^{\prime}(0)f^{\prime}(0)h^2)$. The quadratic term yields a
straight-forward $O(m^{\prime\prime}(0)h^2)$ contribution, and one can verify
(somewhat tediously) that pushing the Taylor expansion of $m$ and $f$ to higher
orders only yields comparatively negligible, $o(h^2)$,
terms. ^ ****: Fan and Yao note in passing
that splines
and additive models date back
to the 1920s, but were simply not practical with that era's computing
technology. (Kernel smoothing goes back to at least the 1950s.) The continued
preference of non-statisticians for linear models over additive models, in
particular, seems to have no basis other than If you really want a modern treatment of statistical theory for time series,
and I confess to a possibly-morbid taste for the stuff, I strongly
recommend Masanobu
Taniguchi and Yoshihide
Kakizawa, Asymptotic
Theory of Statistical Inference for Time Series,
and Bosq and Blanke,
Inference and Prediction in Large Dimensions. ^ignorance
historical inertia.
*****: Cf. this paper by Reilly and Zeringue, recently highlighted by Andrew Gelman. For that matter, this is the approach advocated by Guttorp in his great Stochastic Modeling of Scientific Data. ^
Hardback, ISBN 978-0-387-95170-6; paperback, ISBN 978-0-387-26142-3