Quantifying Self-Organization, Especially in Cellular Automata
Update, September 2004: This talk is now quite old, and in
some ways outmoded, particularly the discussion of computational mechanics and
complexity measures towards the end. I think that they give us a good way of
quantifying self-organization, but more refined techniques are needed. Please
see Cosma Rohilla Shalizi, Kristina Lisa Shalizi and Robert Haslinger,
"Quantifying Self-Organization with Optimal Predictors", Physical Review
Letters 93 (2004): 118701, freely available as nlin.AO/0409024. What follows
is, aside from minor corrections, just what I wrote in 1996.
Abstract: Most decisions about whether something is self-organizing or
not are made at an intuitive, "I know it when I see it" level. The talk will
explain why this is unsatisfactory, describe some possible quantitative
measures of self-organization from statistical mechanics and from complexity
theory, and test them on several different cellular automata whose
self-organization, or lack thereof, is not in dispute
Why Quantify?
It's all but impossible to open up a book or a collection of articles on
complexity, or systems, or "neat non-linear nonsense" in general, without
finding some mention of self-organization, and indeed there are whole schools
of thought (e.g. Prigogine and
Stengers, 1984) for whom the notion has postively mystical import. It is
also all but impossible to find anyone who will say what "self-organization"
means, or how we know that some things are self-organizing and others are not.
At best we rely on intuition: "I know it when I see it."
Such a standard may be good enough for artists, pornographers, and the
Supreme Court, but it is intrinsically unsatisfying in exact sciences, as we
fondly imagine ours to be. Moreover it is infertile and unsound.
By "infertile" I mean that we can't build anything on it. It would be very
nice, for instance, to have some kind of theory about what kinds of
things are self-organizing, or what the common mechanisms of self-organization
are, and the like; but we can't do this if we rely on our eyes, or guts, or the
pricking of our thumbs.
What's worse is that our intuitions are likely to be bad ones. This is, in
part, because the idea is quite new; the oldest use of the word
"self-organizing" I have been able to find was in 1947, though kindred notions are a bit older. We've had
art and smut since the Old Stone Age, and it's still not at all clear that we
recognize them when we see them. We've had faces for even longer, and probably
our most reliable intuitive judgements of the emotions of other people, which
are bad enough for actors, con-artists and poker-players to prosper. And this
is despite the fact that there must have been enormous selective pressure,
throughout our evolutionary history, for the ability to read emotions; but
probably none at all for even rudimentary talent at recognizing
self-organization.
What talent at this we do have depends mostly on our ability to visualize
things, though we could probably accomplish something accoustically. (I don't know of any work on data "audization.") This
restricts us to three dimensional problems; four if we animate things. But
we'd like to be able to attack ten- or fifty- dimensional problems, which are
likely to be very common in fields like ecology or morphogenesis. Even if we
can look at things, we often miss patterns because of the coding, or because we
haven't learned to see them, or simple dumb luck. I, for instance, no matter
what I do to myself, can see nothing beyond vaguely psychedelic lines in those
"Magic Eye" pictures, but I take it on trust that the rest of you can.
Conversely, we are also good at seeing patterns where there aren't any: castles
in clouds, a face in two dots and a curved line; the "chartists" who practice
witch-craft on graphs of securities prices purport to see ducks and geese and
all manner of beasts therein. Las Vegas and state lotteries make millions if
not billions because of our inability to recognize absences of pattern.
Given all this, one would expect disputes about whether or not some things
are self-organizing, and indeed there have been fairly heated ones about
turbulence (Klimontovich, 1991)
and ecological succession (Arthur,
1990). With intuition, such disputes are resolved only by journal editors
getting so tired of them they reject all papers on the subject. If, on the
other hand, we can formalize self-organization, then disputants "could sit down
together (with a friend to witness, if they like) and say `Let us calculate,' "
or at any rate know what they would need to learn before being able to
calculate.
We need, then, to formalize the idea of self-organization, and really
quantifying it would be ideal, since then we could order processes from most to
least self-organizing, and make graphs, and generally hold our heads high in
the presence of mathematical scientists. Whatever we come up with must,
however, have some contact with our current intuitions, or else we're
not really addressing the problem at all, but changing the subject. So my strategy will be to look at some things which
everyone agrees are self-organizing, and some others which everyone agrees are
not, and try to find something which accepts all the former, and rejects all
the latter; then we can use it to resolve debates about things in between.
How to Quantify? --- Statistical Mechanics
Self-organization is about emergent properties (among
other things) and statistical mechanics is the first and most successful study
of emergents, so it's a logical place to start looking. (A single molecule
doesn't have a pressure or a specific heat.) In fact, the received opinion
among physicists --- going back to Ludwig Boltzmann, and to J. Willard Gibbs
--- is that entropy measures disorder (Gibbs said "mixedupness"), and in fact
ever since the rise of biophysics and molecular biology it's been identified
with the opposite of biological organization --- in What Is Life?
Schrödinger has a detailed description of how living things "feed" on
negentropy.
Furthermore, I've been able to find only two instances of someone doing
calculations to figure out whether something is self-organizing, and both of
them use entropy as their criterion. Stephen Wolfram's famous paper on "Statistical Mechanics of Cellular Automata"
(1983) does it for some of his "elementary" CA, and Yu. L. Klimontovich
(in Turbulent Motion and the
Structure of Chaos) attempts to show that turbulence is
self-organized, as compared to laminar flow, by calculating entropy production
in the two regimes; the book, alas, suffers from the worst translation and
editing I have ever seen from a pukka academic publisher, making it
unnecessarily hard to see just what Klimontovich has accomplished. (David
suggests that one reason Wolfram did his entropy calculations was because of
the great interest in the dynamical entropies of chaotic maps at the time.)
So, what is entropy? In the discrete case, we imagine that we have
a set of N states (not necessarily the fundamental dynamical states of our
system), and that the probability of being in state i is p_i.
Then the entropy of the distribution over the N states is
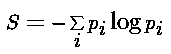 [Post-script, 8k] and this is a maximum when all
the probabilities are equal, hence 1/N, in which case the entropy is log N.
The units will vary depend on which base for our logarithms we choose, and
whether or not we stick a multiplicative constant k out front. In
what follows, I always set k=1, and took logs to the base two, so
entropy is always in bits. (In the continuous case, we replace the sum with an
integral, and the probabilities with a probability density; but all the states
I'll be considering are discrete.)
[Post-script, 8k] and this is a maximum when all
the probabilities are equal, hence 1/N, in which case the entropy is log N.
The units will vary depend on which base for our logarithms we choose, and
whether or not we stick a multiplicative constant k out front. In
what follows, I always set k=1, and took logs to the base two, so
entropy is always in bits. (In the continuous case, we replace the sum with an
integral, and the probabilities with a probability density; but all the states
I'll be considering are discrete.)
This is the traditional entropy formula, which goes back to Boltzmann, but
credit is sometimes shared with Willard Gibbs and Claude Shannon. There's an
infinite family of generalizations of it, called the Renyi entropies, but I
won't deal with them here.
One thing I must deal with, and this is an appropriate place to do so, is
the Second Law of Thermodynamics. It's a common mistake to think that it's a
law of nature which says no entropy may ever decrease, and
this has led to some really bad books about evolution, economics, the novels of
Thomas Pynchon, etc. (References
available upon request.) But this is totally wrong.
In the first, place, the second law is a law of thermodynamics, and
it's only about the thermodynamic entropy, the thing connected to heat
and temperature (TdS = dQ), which comes from the distribution
of kinetic variables (like molecular spins and momenta). If you're looking at
any other sort of entropy, the law is mute. Second, there is in general no
analog of the second law for any other sort of entropy; it's not an independent
law of nature but a consequence of the laws of kinetics, and not a trivial and
easy one; there are proofs of it for only a few cases, like very dilute gases.
Whether or not a system has anything like the second law depends on the
idiosyncrasies of its dynamics. Third, even if you are talking about
thermodynamic entropies, you get guaranteed increases only in closed systems, ones which don't interact
with the rest of the world. Since the Earth and living things are not closed systems, it
really doesn't apply to anything of interest to us.
Qualitatively, what is the entropy saying? Imagine the probability as a
sort of relief map over the state space, made out of modelling clay. High entropy is very flat and even and boring: Nebraska.
Low entropy is uneven, with hills and valleys to make life interesting, like
San Francisco. You've only got so much clay, and you can't throw out any
of it, so any rise in one place has to be made up with a hollow someplace else,
and vice versa. As the entropy decreases, the distribution gets more and more
lumpy (the clay migrates of its own) and so the process selects against more
and more of the phase space, and selects for some small region of it.
(Probably there's a link to "fitness landscapes" in evolutionary biology, but I
haven't worked that out yet.) This idea, of self-organization as selection,
goes back to W. Ross Ashby in the
early days of cybernetics (but he didn't talk about oozing modelling clay: Ashby 1961).
Why Cellular Automata? and What Cellular Automata?
[N.B.: This was the third in a series of three talks on cellular automata,
so I assumed that everybody pretty much knew what CA were. You can get all the
background you need from the CA FAQ
or my own cellular automata
notebook.]
Why Cellular Automata?
I have two major reasons for trying to quantify self-organization in CA first:
- My adviser studies CA.
- If we can quantify self-organization in anything, we can do it in CA.
The first point speaks for itself; the second deserves a bit more elaboration.
In cellular automata, we know what the low-level dynamics are,
because we specify them. They are tractable. They are reproducible. You can
get great big runs of statistics on them. You can prove theorems about them.
They require nothing more than a computer and patience to observe. There are
no tricky problems of measurement. They are, in short, about the best-behaved
and best-understood self-organizers known. If we can't specify what it means
for them to self-organize, it seems very unlikely that we'll do much
better with the Belusov-Zhabotinskii reaction (a.k.a. "sodium geometrate"),
or slime molds,
or learning systems, or economies.
Which Cellular Automata?
First, we want something which does not look self-organizing, to serve
as our control. Any test it passes is a bad indicator of self-organization.
Furthermore, it's more interesting to use something which actually has some
structure, and is not pure noise. The non-linear voter
model (technically, with p(1)=p(2)=0.5), or nlvm,
qualifies. There are 2 colors, for the two political parties; each cell takes
a careful poll of its immediate (N,S,E,W) neighbors' opinions, then looks at
who pays for elections and realizes it might as well flip a coin, so it does --- unless all
its neighbors are of its current opinion, in which case it feels confident
enough to retain it. (This is probably not such a bad model for politics in
the '90s.) It looks rather like noise; certainly it
doesn't look self-organizing.
Next, we want some different self-organizing CA, to help find measures of
self-organization per se, and not just a particular sort of
self-organization. The two seized upon are the majority-voter model
(majority) and a version of the Greenberg-Hastings rule
called macaroni.
Majority
voting is just what it sounds like. As in nlvm, there are two
colors, for the two parties. You look at your neighbors and, being a timid
conformist, switch to whatever most of them are. (This is a model for politics
in the '50s.) Majority undergoes "simply massive self-organization at
the start" (in the words of D. Griffeath) as large clusters form, and then it
moves more slowly, doing "motion by mean curvature" to reduce surface tension
as the clusters expand and their boundaries flatten out. (Vide these snapshots of a typical run
of majority.)
Macaroni, as I
said, is an incarnation of the Greenberg-Hastings rules. Here we have five
colors, numbered from 0 to 4. 0 is a resting state, 1 is an excited state, and
states two through four are excitation decaying back to quiescence. Cells in
states 1--4 automatically increase their number by one with every tick of the
clock (and 4+1=0, of course). Zeroes need to see a certain threshold number of
ones in their vicinity before they too can become excited. In this case, the
neighborhood is a range 2 box (i.e. the 5x5 box centered about the cell in
question), and the threshold is four. With these settings,
we get long cyclic bands of colors rolling across the lattice. (If the
threshold were not so high, they would bend inwards into spiral waves.) The CA
is called macaroni because, with the appropriate choice of colors, the
strings of orange muck remind David of a sort of near-food called "macaroni and
cheese." (I'm prepared to take his word for it; these days starving students
eat ramen.)
All of these were run on a 256x200 grid, with wrap-around boundaries (i.e.,
on a torus).
Now ideally we'd compute distributions of configurations of this whole grid,
i.e. each distinct configuration of the grid would be a state in our
calculation of entropy, and we'd simply count how many examples of each
configuration we had in our sample at a given time. Practically speaking, this
is impossible. There are 2^51,200 (~10^15,413) such for nlvm
and majority, and 5^51,200 (~10^35,787) for macaroni. These
numbers go beyond the astronomical (the number of permanent particles in the
Universe is only about 10^80), and become what the philosopher Daniel Dennett calls Vast. We
are not able to find good distributions on sets that size, at least
not empirically.
Instead what I did was to divide the over-all grid into smaller sub-grids,
into mxm windows:
![[Picture of breaking up the lattice in 3x3
windows]](windows.gif) [Post-script, 10k]. The number of
possible configurations within a window is much smaller than the number of
configurations on the whole grid, and each instance of the CA contains (at
least if m) is small) a great many windows, so we can get
good statistics on this, just by determining which configuration each window
happens to be in. (Once we have the distribution, calculating its entropy is
not a problem.) So for a particular CA, the entropy S is function of
two parameters, the window-size m and the time t. What do
the plots of S(m, t) vs. t look like?
[Post-script, 10k]. The number of
possible configurations within a window is much smaller than the number of
configurations on the whole grid, and each instance of the CA contains (at
least if m) is small) a great many windows, so we can get
good statistics on this, just by determining which configuration each window
happens to be in. (Once we have the distribution, calculating its entropy is
not a problem.) So for a particular CA, the entropy S is function of
two parameters, the window-size m and the time t. What do
the plots of S(m, t) vs. t look like?
In our control case, nlvm, we above
all do not want the entropy to decrease; and in fact we'd like it to be high,
as high as possible. On examination, it is essentially constant, and always
within one part in a thousand of the maximum. So entropy passes its first
test, of saying that nlvm isn't self-organizing. It also behaves in a
most gratifying way in the case of majority, where the entropy drops
drastically in the first few clicks ("massive self-organization at the start,"
yes?), and then declines more sedately.
When we come to macaroni, on
the other hand, things are more complicated. There is a very sharp
decrease in the entropy initially, followed by a slow increase, which levels
off at a fraction of the initial entropy. This is because most cells die off
very quickly (the zeroes are not excited, and all the other cells cycle down to
zero), except for a few centers of excitation, which then gradually extend
their waves; as this happens there's some differentiation, and less dead space,
which increases the entropy. In a sense the entropy works here too ---
it does show an over-all decline, after all --- but the situation is
disturbing for a number of reasons, which I'll get to anon.
(As a technical aside, I suspect there's some trickery with the
renormalization group which could be used to relate the entropies for different
window-sizes, but I haven't really looked into the matter.)
What's Wrong with Entropy?
As things stand, the answer is, "Lots." These can be roughly divided into two
sorts, practical problems, which can be mitigated through care and cleverness,
and conceptual problems, which cannot.
Practical Problems
The first practical problem, and probably the easiest one to deal with, is that
of the initial set, since this sets our baseline for comparative judgements of
order. If the initial set is biased, we could get really weird
results. --- If we'd walked in on macaroni about t=10, the
entropy would suggest that it's self-disorganizing. This may actually
be less of a problem for physical experiments than for computer
models, since Nature is better at creating a mess than programmers are at
writing pseudo-random number generators.
Next we must deal with the number and quality of our data. Accurate
calculations need lots of it, it can't be very noisy, and the parameters can't
be shifting around under our feet (at least, not in some uncontrolled way).
This isn't really a problem for CA --- I have 10^6 data-points for the window
distributions, though even then I'd like more for macaroni, --- but
what about chemistry, or, heaven help us, economics?
At this point it's worth saying a word about error margins. We can
calculate the sampling error in our value of the entropy if we know the
underlying distribution. (There are even analytic expressions if the
distribution is uniform.) It has the annoying property of increasing as the
true entropy decreases.
The most serious problem is that of memory size. Observe that m,
the window size, is picayune, never more than 3 or 4. If I wanted to go beyond
that, I'd go to 2^25 or 5^16 configurations, and (a) I don't have enough
data-points and (b) I don't have enough memory (120 and 610,00 Mb,
respectively) to figure out what the distribution is. (If we could only do
that, calculating its entropy would present no special difficulties.) ---
Clever data structures can bring down the memory requirements if the
entropy is a lot lower than the theoretical maximum, but even if only 1
configuration in 10^4 occurs that's still 60Mb, and the next increment pushes
us up to 690 Mb and 100 million Mb, respectively. It is, in short, a loosing
proposition if there ever was one.
Conceptual Problems with Entropy
First: It's a statistical measure, which really only applies to ensembles of
systems, and tells us about their behavior in aggregate. But, personally, if I
mixed some sterile chemicals up and forty days later something crawled out, I'd
say that particular bunch of chemicals had self-organized. Maybe I'm wrong.
Second, there is what I call the "Problem of the Ugly Ducklings." Suppose I
have a rule where everything gravitates to configurations which look like this:
![[A picture of a random macaroni initial state]](macaroni/0.jpg) and these are very thin in the set of configurations, making the entropy very
small. This could mean that entropy doesn't work as a measure of
self-organization. Or we could take it as a sign that we've over-looked the
distinctive merits of these beasts, and doubtless a determined search would
turn up some structure...
and these are very thin in the set of configurations, making the entropy very
small. This could mean that entropy doesn't work as a measure of
self-organization. Or we could take it as a sign that we've over-looked the
distinctive merits of these beasts, and doubtless a determined search would
turn up some structure...
The third problem --- which is, perhaps, just the second in another guise
--- is that some of the more thoughtful biologists have had real
reservations about entropy being the measure of biological organization.
"Biological order is not just unmixedupness." (Medawar). --- In fact the biologists have a
rather extensive literature on what they mean by "organization," which I need
to explore. This is, I think, an important objection, not least because
our secret ambition is to be able one day to throw up our hands and say "It's
alive!" A putative measure of self-organization which doesn't work on the most
interesting instance of self-organization, namely those in living things,
probably isn't worth very much, though it could show that the
similarities between organic and inorganic self-organization are only
superficial.
Correlation Lengths
The correlation length arises from the standard statistic called Pearson's
correlation coefficient, or just the correlation, between two variables, which
measures how much influence one has upon the other. The idea of a
correlation length comes from making the two variables the values of
the same variable separated by some distance r. You can then work out
the correlation function C(r), and it often happens that it has a form
like C(r) = f(r) exp(-r/l), where f(r) is
less-than-exponential. Then the distance l is "characteristic" of the
correlation, and is called the correlation length. (Mutatis mutandis,
this is how one figures out correlation times, as well.) One criterion for
self-organization, at least over space, would be an increase in the correlation
length, and strong self-organization would happen when it goes to infinity, and
the exponential term in the correlation function drops out, as is supposed to
happen in self-organized criticality.
At this point I'd like to show you some graphs of the correlation length
climbing steadily upwards, but I can't, because I made a silly mistake in my
code.
Anyway, there are some substantial problems with the correlation length.
The first is that Pearson's correlation really only catches simple linear
dependence, so that, say, periodic processes don't have a well-defined
correlation length. This can perhaps be evaded, as there are other sorts of
characteristic length we can take out of our toolkit and compute. More
seriously, many of the things we consider self-organizing don't really look
spatial, or at least not importantly so. I find it hard to believe that the
difference between my chess and Kasparov's (or Deep Thought's) is captured by
a length; though there may be some very strange and abstract space
where this is so.
How to Quantify --- Complexity
We suspect entropy, or entropy alone, isn't what we need. So a way of
characterizing the final states (or the processes which lead to them) and lets
us avoid ugly ducklings and the like would be very nice. A sensible place to
start looking for this is in the various measures of complexity.
Kolmogorov, or algorithmic, complexity
The basic idea is that you have a bit string and ask, what's the shortest
program which could make that string? (Normalize for the string length). Very
repetitive strings, or easily calculated ones, have low Kolmogorov complexity,
but random numbers (whatever they are) have maximal Kolmogorov complexity.
Kolmogorov complexity's usual role in discussions like this is to be
solemnly exhibited and equally solemnly put away unused, since it's pretty much
impossible to calculate it for anything real. And since it's just
gauging randomness it has all the conceptual disadvantages of entropy as well
as being even worse to calculate, and assuming on top of things that
whatever you're studying is essentially a digital computer.
What we want (or so at least David says, and on alternate days I agree with
him) is something which is small for both very ordered (low Kolmogorov
complexity) patterns and very random (high Kolmogorov complexity) ones, since
in a sense pure randomness is disgustingly simple --- just flip coins.
There are at least two such measures: Lloyd and Pagel's depth, and Crutchfield's statistical
complexity.
As with the Kolmogorov complexity, we need to construct a machine, a computer
to match our bit stream; but we want to match its grammar and
statistical properties. What we find is some sort of automaton with
internal states, and a probability distribution over those states. The
complexity C of the machine is said to be the entropy of that
distribution. The complexity of the data is that of the least complex machine
reconstructed from it.
We have the problem of turning 2+1 dimensional data into a 1 dimensional
stream of bits. This can be done in infinitely many ways, and maybe ones which
look strange to us would lead to much smaller complexities.
One way around this --- vide Crutchfield (1992), Crutchfield and Hanson (1993) --- is to try
to find persistent domains where the spatial pattern is easy to
describe (and it's easy to find the complexity of the corresponding automaton).
Then you can filter out those domains and try to find patterns for what's left.
This is part of a more general approach of Crutchfield et al. which
they call "computational mechanics"; I'll say more about this towards the end.
(Another advantage of this approach is that it makes it easier to calculate the
entropy!)
Long runs of consistent data are still needed, because the approach
looks at "the statistical mechanics of orbit ensembles." Coin-tossing should
has C=0; to convince myself I understood the technique I sat down and
flipped a penny thirty-two times and came up with a seven state machine
with C ~ 2.8 bits.
When I can get my code to work, I'll turn it loose on NLVM and
the Cyclic Cellular Automaton, CCA, where we already have formal
characterizations of the structures found (Fisch, Gravner and Griffeath, 1991);
it will be good to see if these techniques come up with the same ones.
Depth
Depth is a complexity measure introduced by Lloyd and Pagels (1988), which applies to
processes, not numbers or states, which I find philosophically appealing; it
subsumes a couple of other, computational measures of complexity; and it does
not assume that the process is basically one of computing (which I also like).
Suppose the process went through a sequence of states a, b, .... c,
d in that order. (These are not necessarily the fundamental, microscopic
states involved in the dynamics, but more like what are called "events" in
probability theory.) The conditional
probability p(ab...c|d) is then the probability of
having taken the trajectory ab...c to arrive at state d. The
average depth of state d is then the entropy of this conditional
probability distribution. (Lloyd & Pagels point out that Occam's razor
suggests we use the depth of the shallowest path to d as the depth
of d, but this is a subtlety.) --- In general the depth of a state
changes over time.
In principle, this just needs empirical experimental data about the
probability of various trajectories; essentially all we have to assume is that
it has states, in some meaningful sense.
Unfortunately, we've seen some of the difficulties of getting good
distributions, and for measuring depth we need not just distributions at a
given time, but distributions of states at many times, and their connections,
which in the worst case will also increase exponentially.
Summary
I hope I've persuaded you that we ought to make self-organization more
rigorous, and bring it closer to quantification, and that it's not completely
hopeless. Currently the plausible measures which we can calculate
aren't that plausible; the ones which are more plausible either demand absurd
computational resources, or are tricky. Everything needs really good
statistics.
At this point I think we have three possibilities:
- We need to be clever. Neat hacks can work wonders. Newton's law
of gravity would be worthless if you couldn't pretend extended objects are
concentrated at their centers of mass. Entropy would be useless in
thermodynamics if it weren't for the connection to heat and temperature, and
maybe similar relations hold in other cases.
- We need to vulgarize. Something which usually tracks the
entropy, but is easier to calculate, would be very useful.
- We need to give up. The machine-reconstruction/computational
mechanics approach is one fall-back position, since it does give us a way of
characterizing what self-organization produces, even when we can't extract
numbers out of it. There are well-defined hierarchies of different sorts of
automata, going back to Chomsky, and one could, say, identify the complexity of
a CA with that of the highest automaton in its model. (Probably all of the
"bugs" Kellie Evans talked about last week are in the same model class, and
this is probably not that of blinkers and blinker-like objects, since one group
is bounded in space, and the other is not.) Doubtless there are other tools we
could force into service, from deeper into abstract algebra and mathematical
logic, as well, like Russell and Whitehead's notion of "structure" or "relation
number" (see Russell 1921).
References
- Wallace Arthur (1990), The Green Machine:
Ecology and the Balance of Nature. Cambridge, Mass., and Oxford: Basil
Blackwell.
- W. Ross Ashby (1947), "Principles of the
self-organizing dynamic
system," J. Gen. Psychol. 37, 125--8 [I have not
read this, but it is cited by Ashby
(1961). Most authors, following Marshall C. Yovits in his preface
to Self-Organizing Systems, 1962 (Washington, D.C.: Spartan
Books), claim that "The term ... was first used by Farley and Clark in 1954 in
their paper in the Transactions of the Institute of Radio
Engineers, Professional Group on Information theory," but this would seem to be
in error.]
- W. Ross Ashby, "Principles of the self-organizing
system", pp. 255--278 of Heinz Von Foerester and George W. Zopf, Jr.,
eds., Principles of Self-Organization: Transactions of the University of
Illinois Symposium on Self-Organization, Robert Allerton Park, 8 and 9 June,
1961; Sponsored by Information Systems Branch, U.S. Office of Naval
Research. NY: Pergamon Press, 1962.
- Noam Chomsky (1957), Syntactic
Structures. Janua Linguarum, Series Minor, Nr. 4. The Hague: Mouton.
- James P. Crutchfield (1992), "Discovering
Coherent Structure in Nonlinear Spatial Systems," in Nonlinear
Dynamics of Ocean Waves, A. Brandt, S. Ramberg, and M. Shlesinger,
editors, World Scientific, Singapore (1992) 190--216 [On-line]
- James P. Crutchfield and James E. Hanson
(1993), "Turbulent Pattern Bases for Cellular Automata," Physica
D 69, 279--301 [On-line;
a very detailed application to a one-dimensional CA]
- James P. Crutchfield and Karl Young
(1989), "Inferring Statistical Complexity," Physical Review
Letters 63, 105--108 [But see Crutchfield (1992) for a more tutorial
introduction]
- Robert Fisch, Janko Gravner and
David Griffeath (1991), "Cyclic Cellular Automata in Two Dimensions" in
Kenneth Alexander and Joseph Watkins (eds.), Spatial Stochastic
Processes: A Festschrift in Honor of Ted Harris on his Seventieth
Birthday (Boston: Birkhäser), pp. 171--188.
- Yuri Lvovich Klimontovich
(1991), Turbulent Motion and the Structure of Chaos: A New Approach
to the Statistical Theory of Open Systems. Translated from the Russian
by Alexander Dobroslavsky. Dordrecht and Boston: Kluwer Academic Publishers,
1991. [An interesting book, suffering from the worst translation and
production I have ever seen.]
- Seth Lloyd and Heinz Pagels (1988),
"Complexity as Thermodynamic Depth," Annals of
Physics 188, 186-213
- Peter Medawar (1982), "Herbert Spencer and
General Evolution" in Pluto's Republic. Oxford and New York:
Oxford University Press.
- Joseph Needham (1937), Order and
Life. Cambridge, Mass.: MIT Press Paperbacks, 1968.
- Joseph Needham (1976), "Integrative Levels"
in Moulds of Understanding: A Pattern of Natural Philosophy.
Edited and introduced by Gary Werskey. London: Allen & Unwin.
- Norman Packard and Stephen Wolfram
(1985), "Two-Dimensional Cellular Automata," Journal of Statistical
Physics 38, 901--946; reprinted in reprinted in Wolfram (1994), 211--249
- Ilya Prigogine and Isabelle Stengers
(1984), Order Out of Chaos: Man's New Dialogue with Nature.
Foreword by Alvin Toffler [!]. New York: Bantam Books.
- Willard Van Orman Quine (1960), Word and
Object. Cambridge, Mass.: MIT Press.
- Bertrand Russell (1921), Introduction to
Mathematical Philosophy. New York: Dover Publications. (First
published London: G. Allen & Unwin.)
- Stephen Wolfram (1983), "Statistical Mechanics
of Cellular Automata," Reviews of Modern
Physics 55, 601--644; reprinted in Wolfram (1994), 3--69
- Stephen Wolfram (1994), Cellular Automata
and Complexity: Collected Papers. Reading, Mass.: Addison-Wesley.
Put on-line 19 May 1996; last revised 16 August 1997 (thanks to Isa Bernardini
and Mitchell Porter for pointing out typos)