The simplest sort of random process is just a sequence of independent random variables. This is truly memoryless, since nothing that happens at any time has any bearing on what happens at any other time. As every schoolchild knows, the first step away from this, in the direction of more memory, is a Markov chain is a sequence of random variables $X_1, X_2, \ldots X_n, \ldots \equiv X_1^{\infty}$ where conditioning on the present state $ X_t $ makes the the future $X_{t+1}^{\infty}$ statistically independent of the past $X^{t-1}_1$. In most natural situations, the conditional distribution $\Pr{\left( X_{t+1}| X_t =x\right)}$ is the same for all $t$, and the chain is "homogeneous". In addition to being a step towards memory and consequences, homogeneous Markov processes are the obvious way of adding noise in to a deterministic dynamical system.
One way of thinking about how Markov chains work is to say that there is some set of probability distributions which $X_{t+1}$ could be generated from, and which of those distributions gets used is a function of $X_t$. We add yet more memory by moving to a higher-order Markov chain, in which the future is independent of the past given (say) $X^t_{t-d}$, then amounts to saying that the distribution used to generate $X_{t+1}$ is a function of $X^t_{t-d}$.
In this perspective, which distribution we use to generate $X_t$ is itself random. Call this random, distribution-valued variable $S_t$. In a first order chain, distinguishing between $X_t$ and $S_{t+1}$ is pedantry. In a higher-order chain, we can either say that $S_{t+1}$ is a function of $X^{t}_{t-d}$, or that $S_{t+1} = u(S_t, X_t)$ for some updating function $u$. For the higher-order chain, again, the updating function is trivial, so this is a bit pedantic, but it opens the door to a much more general situation.
Consider a stochastic process with two sequences of random variables. $X_t$ takes values in whatever space we like, say $\Xi$; then the values of $S_t$ are points in some set $ \Sigma $ of probability distributions over $\Xi$. We also have an update function $ u $, with, again, $S_{t+1} = u(S_t, X_t)$. At time $ t $, we draw $ X_t $ from the distribution $ S_t $, independently of all that has gone before; then we apply $ u $ to get $ S_{t+1} $ and go on. This is the most basic form of what Iosifescu and Grigorescu call a "random system with complete connections".
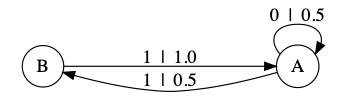
It is clear from this description that the joint sequence $ (X_t, S_t) $ is a Markov process. It is also not hard to convince oneself that $ S_t $, considered by itself, is Markov. (Iosifescu and Grigorescu call it the "associated chain".) But the $ X_t $ sequence, the "chain with complete connections", need not be a Markov process, not even a higher-order Markov process. The easiest example of this, due to Benjamin Weiss, is the "even process": $ X_t $ is binary, $ \Xi = \left\{ 0, 1\right\} $, and there are likewise just two distributions in $ \Sigma $: one, call it A, one splits the probability 50-50 between 0 and 1, and the other, call it B, puts all the probability on 1. The update function is that \[ \begin{eqnarray*} u(A,0) & = & A\\ u(A,1) & = & B\\ u(B,1) & = & A\\ u(B,0) & = & \mathrm{never\ called\ for} \end{eqnarray*} \] We can put the whole model in graphical form:
If we examine $ X_t $, the "chain with complete connections", we find that it consists of even-length blocks of 1s, separated by blocks of 0s whose length may be odd or even. This keeps it from being a Markov chain of any finite order. (Exercise: prove this last sentence.) This in turn shows that while every (discrete-time1) Markov process qualifies as a random system with complete connections, the latter form a strictly larger class of stochastic processes. I should add that it is not necessary for $ S_t $ to be a measure-valued variable; we can have it live in whatever space we like, and introduce a transition or emission probability function, which it is sometimes convenient to allow to vary with time: $ p_t(s,A) = \Pr{\left(X_t \in A|S_t = s\right)} $.
A random system with complete connections, then, extends the notion of a Markov process to cases where the state of the system is not fully observed. One might well then ask how it differs from the more widely-used notion of a hidden Markov model. In an HMM, after all, there is also an observed observed non-Markovian sequence $ X_t $, and a latent Markov process $ S_t $, where each $ X_t $ is generated from a distribution specified by $ S_t $. The difference is subtle but important. In a chain with complete connections, $ S_{t+1} $ is a function of $ S_t $ and $ X_t $, but in a hidden Markov model, $ S_{t+1} $ is independent of $ X_t $ given $ S_t $. This coupling between the observed sequence and the latent transitions is, for those raised on HMMs, odd and takes some getting used to. As has been discovered many times, however (most recently, here), when one tries to predict an HMM, one deals not with individual latent states but with distributions over those states, and the evolution of those distributions follows, precisely, a random system with complete connections. The same class of models has also arisen in symbolic dynamics ("sofic shifts", "finitary measures"), and in theoretical computer science (though I will leave the latter to a footnote2) and statistical mechanics.
The idea of a chain with complete connections is actually substantially older than that of a hidden Markov model, going back (at least) to a paper by Onicescu and Mihoc in 1935. As these names suggest, there has been a school of work in this area in Romania ever since. This book is the latest in a series of works on the results obtained by this school3. As such, Dependence with Complete Connections provides a thorough, if very pure-mathematical, account of the structure and ergodic theory of these stochastic processes.
The first chapter is given over to basic definitions (with slightly different notation than I have used), and a large collection of stochastic systems which can be put into this form. The second chapter looks for basic analogies between the usual ergodic theory of Markov processes and the behavior of random systems with complete connections, especially the chain with complete connections $ X_t $.
The third chapter, in many ways the most intricate and technical of the book, is concerned with the ergodic decomposition of the associated chain $ S_t $, in particular finding conditions which will guarantee a finite number of ergodic components and a rapid passage out of transient parts of the state-space and into recurrent ones. Many of the results obtained in this chapter are in fact quite general ones about Markov processes satisfying (e.g.) certain continuity conditions on their transition operators, whether or not these arise from a random system with complete connections.
In chapter four, these results about the associated chain $ S_t $ are used to derive results about the observable sequence $ X_t $ --- notably, a pointwise ergodic theorem, an ordinary and functional central limit theorem (with some information about rates), a Glivenko-Cantelli theorem and a law of the iterated logarithm. (Events which happened a very long time ago are never forgotten, exactly, but they have less and less effect as they recede into the past.) The final chapter consists of applications: to chains with complete connections where $ \Xi $ is finite, to iterated maps of the interval, and to purely mathematical topics (like continued fractions) which, not being a pure mathematician, I found uninteresting.
Throughout, the exposition is quite clear, though very formal and mathematically demanding. In principle, appendices which review all necessary notions of measure theory, stochastic processes, Markov operators, mixing, and functional analysis make the book self-contained. In reality, the implied reader needs a quite firm grasp of the measure-theoretic treatment of Markov processes, and especially of Markov operators, at the level of Lasota and Mackey at the least. Familiarity with topics like mixing coefficients or the functional central limit theorem is less essential, but would still help. With that understanding, I recommend this to anyone with a serious theoretical interest in stochastic processes especially in alternatives to HMMs.
1: One can imagine making the same sort of set-up work in continuous time. One has to let $ S_t $ be a distribution not just over the next observation $ X_t $, since there is no next observation, but over whole future trajectories. (We could do this in discrete time, too, but it's needless work there.) The updating then would take the form $ S_{t+\tau} = u(S_t, X_t^{t+\tau}) $. If you are the kind of person to who reads something like this and wonders about the many, many measure-theoretic technicalities it raises, I recommend you read the late Frank Knight on "prediction processes", starting with "A Predictive View of Continuous Time Processes" (Annals of Probability 3 (1975): 573--596). Indeed, Knight showed that basically every stochastic process can be represented in this form. (This link is not made in this book.) ^
2: When both the space for observables $ \Xi $ and the space of latent states $ \Sigma $ are finite, a random system with complete connections becomes identical with what computer scientists call probabilistic (or stochastic) deterministic finite automata. "Probabilistic deterministic" is not an oxymoron here, since, to automata-theorists, "deterministic" indicates precisely that the current state $ S_t $ and observation $ X_t $ jointly determine the next state $ S_{t+1} $ through the update function, $ S_{t+1} = u(S_t, X_t) $, as opposed to leaving open a choice of next states, as in a non-deterministic finite automaton. In the non-probabilistic case, deterministic and non-deterministic finite automata have the same expressive power. In the probabilistic but finite case, non-deterministic automata are actually more powerful; but I believe the distinction goes away again when we allow for an infinity of states. The connection with automata theory is not, however, noted by our authors. ^
3: It's worth recalling here that there are two basic existence theorems for stochastic processes. The better known one, due to Daniell and then, in a more general form, to Kolmogorov, says that if your specification tells you all the finite-dimensional distributions and they are compatible with each other under projection, then there is a unique infinite-dimensional distribution with all those finite-dimensional projections. The other existence theorem, due to Ionescu Tulcea, says that if your specification gives you the conditional distribution of $ X_{t+1} $ given $ X_1^t $ for each $ t $, there is a unique extension to an infinite-dimensional distribution. Interestingly, neither one reduces to the other. (For proofs, see chapters 2 and 3 of Almost None of the Theory of Stochastic Processes.) Whether the Ionescu Tulcea theorem and the Onicescu and Mihoc paper on chains with complete connections are part of some larger early-20th-century Romanian tradition of interest in conditional probability, I don't know. For that matter, I suspect there may be an interesting science-under-Communism story as to how this line of mathematical research was kept going in Romania. ^