"Can't seem to face up to the facts"
Attention conservation notice: An academic paper you've never heard of, about a distressing subject, had bad statistics and is generally foolish.
Because my so-called friends like to torment me, several of them made sure that I knew a remarkably idiotic paper about power laws was making the rounds, promoted by the ignorant and credulous, with assistance from the credulous and ignorant, supported by capitalist tools:
- M. V. Simkin and V. P. Roychowdhury, "Stochastic modeling of a serial killer", arxiv:1201.2458
- Abstract: We analyze the time pattern of the activity of a serial killer, who during twelve years had murdered 53 people. The plot of the cumulative number of murders as a function of time is of "Devil's staircase" type. The distribution of the intervals between murders (step length) follows a power law with the exponent of 1.4. We propose a model according to which the serial killer commits murders when neuronal excitation in his brain exceeds certain threshold. We model this neural activity as a branching process, which in turn is approximated by a random walk. As the distribution of the random walk return times is a power law with the exponent 1.5, the distribution of the inter-murder intervals is thus explained. We confirm analytical results by numerical simulation.
Let's see if we can't stop this before it gets too far, shall we? The serial killer in question is one Andrei Chikatilo, and that Wikipedia article gives the dates of death of his victims, which seems to have been Simkin and Roychowdhury's data source as well. Several of these are known only imprecisely, so I made guesses within the known ranges; the results don't seem to be very sensitive to the guesses. Simkin and Roychowdhury plotted the distribution of days between killings in a binned histogram on a logarithmic scale; as we've explained elsewhere, this is a bad idea, which destroys information to no good purpose, and a better display is shows the (upper or complementary) cumulative distribution function1, which looks like so:
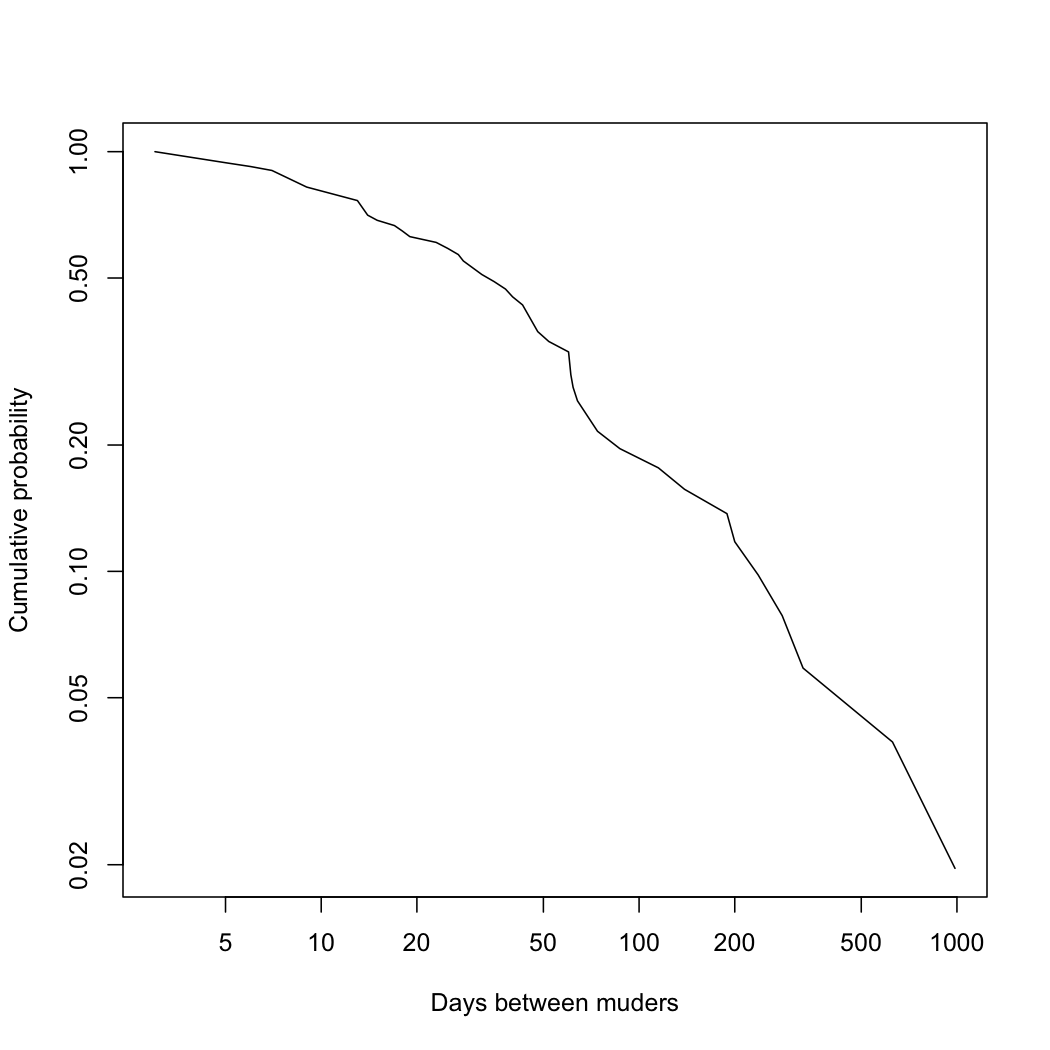
When I fit a power law to this by maximum likelihood, I get an exponent of 1.4, like Simkin and Roychowdhury; that looks like this:
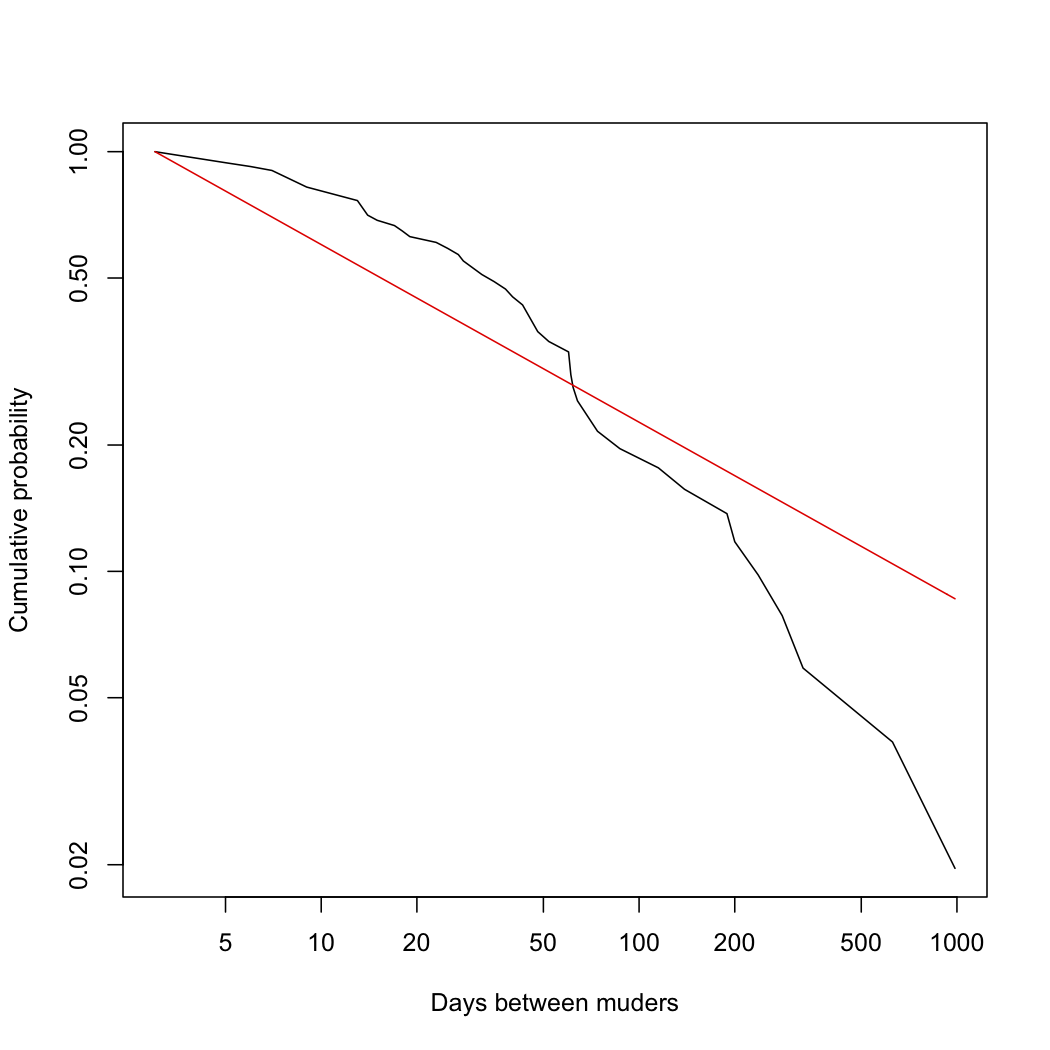
On the other hand, when I fit a log-normal (because Gauss is not mocked), we get this:

After that figure, a formal statistical test is almost superfluous, but let's do it anyway, because why just trust our eyes when we can calculate? The data are better fit by the log-normal than by the power-law (the data are e10.41 or about 33 thousand times more likely under the former than the latter), but that could happen via mere chance fluctuations, even when the power law is right. Vuong's model comparison test lets us quantify that probability, and tells us a power-law would produce data which seems to fit a log-normal this well no more than 0.4 percent2 of the time. Not only does the log-normal distribution fit better than the power-law, the difference is so big that it would be absurd to try to explain it away as bad luck. In absolute terms, we can find the probability of getting as big a deviation between the fitted power law and the observed distribution through sampling fluctuations, and it's about 0.03 percent2b [R code for figures, estimates and test, including data.]
Since Simkin and Roychowdhury's model produces a power law, and these data, whatever else one might say about them, are not power-law distributed, I will refrain from discussing all the ways in which it is a bad model. I will re-iterate that it is an idiotic paper — which is different from saying that Simkin and Roychowdhury are idiots; they are not and have done interesting work on, e.g., estimating how often references are copied from bibliographies without being read by tracking citation errors4. But the idiocy in this paper goes beyond statistical incompetence. The model used here was originally proposed for the time intervals between epileptic fits. The authors realize that
[i]t may seem unreasonable to use the same model to describe an epileptic and a serial killer. However, Lombroso [5] long ago pointed out a link between epilepsy and criminality.That would be the 19th-century pseudo-scientist3 Cesare Lombroso, who also thought he could identify criminals from the shape of their skulls; for "pointed out", read "made up". Like I said: idiocy.
As for the general issues about power laws and their abuse, say something once, why say it again?
Update 9 pm that day: Added the goodness-of-fit test (text
before note 2b, plus that note), updated code, added PNG versions of figures,
added attention conservation notice.
21 January: typo fixes (missing pronoun, mis-placed decimal point), added
bootstrap confidence interval for exponent, updated code accordingly.
Manual trackback: Hacker News (do I really need to link to this?), Naked Capitalism (?!); Mathbabe; Wolfgang Beirl; Ars Mathematica (yes, I am that predictable); Improbable Research (I am not worthy)
1: This is often called the "survival function", but that seems inappropriate here.
2: On average, the log-likelihood of each observation was 0.20 higher under the log-normal than under the power law, and the standard deviation of the log likelihood ratio over the samples was only 0.54. The test statistic thus comes out to -2.68, and the one-sided p-value to 0.36%.
2b: Use a Kolmogorov-Smirnov test. Since the power law has a parameter estimated from data (namely, the exponent), we can't just plug in to the usual tables for a K-S test, but we can find a p-value by simulating the power law (as in my paper with Aaron and Mark), and when I do that, with a hundred thousand replications, the p-value is about 3*10-4.
3: There are in fact subtle, not to say profound, issues in the sociology and philosophy of science here: was Lombroso always a pseudo-scientist, because his investigations never came up to any acceptable standard of reliable inquiry? Or just because they didn't come up to the standards of inquiry prevalent at the time he wrote? Or did Lombroso become a pseudo-scientist, when enough members of enough intellectual communities woke up from the pleasure of having their prejudices about the lower orders echoed to realize that he was full of it? However that may be, this paper has the dubious privilege of being the first time I have ever seen Lombroso cited as an authority rather than a specimen.
4: Actually, for several years my bibliography data base had the wrong page numbers for one of my own papers, due to a typo, so their method would flag some of my subsequent works as written by someone who had cited that paper without reading it, which I assure you was not the case. But the idea seems reasonable in general.
Posted at January 17, 2012 20:23 | permanent link